
Goliaths Playing At David
How AI fear crushed the indie creator of ProseCraft.io for no good reason
I’m a writer, but this will be a story criticizing writers.
I plan to debut a novel someday, and I know this may hobble my chances. The lit crowd is a close-knit and cliquey sort.
But I’ll do it anyway, because that’s what you do when giants go curb-stomping underdogs.
The demise of ProseCraft.io

A few days ago, an independent creator had to take down his labor of love—ProseCraft.io—after crushing pressure from the writing community.
ProseCraft was a project that had launched in 2017 and hadn’t actively maintained a blog presence since 2019, so this sudden and acute backlash must’ve been jarring, to say the least.
Even more surprising: ProseCraft.io seemed to just publish summary statistics on novels, with word frequencies and a few exotic metrics like “vividness”.
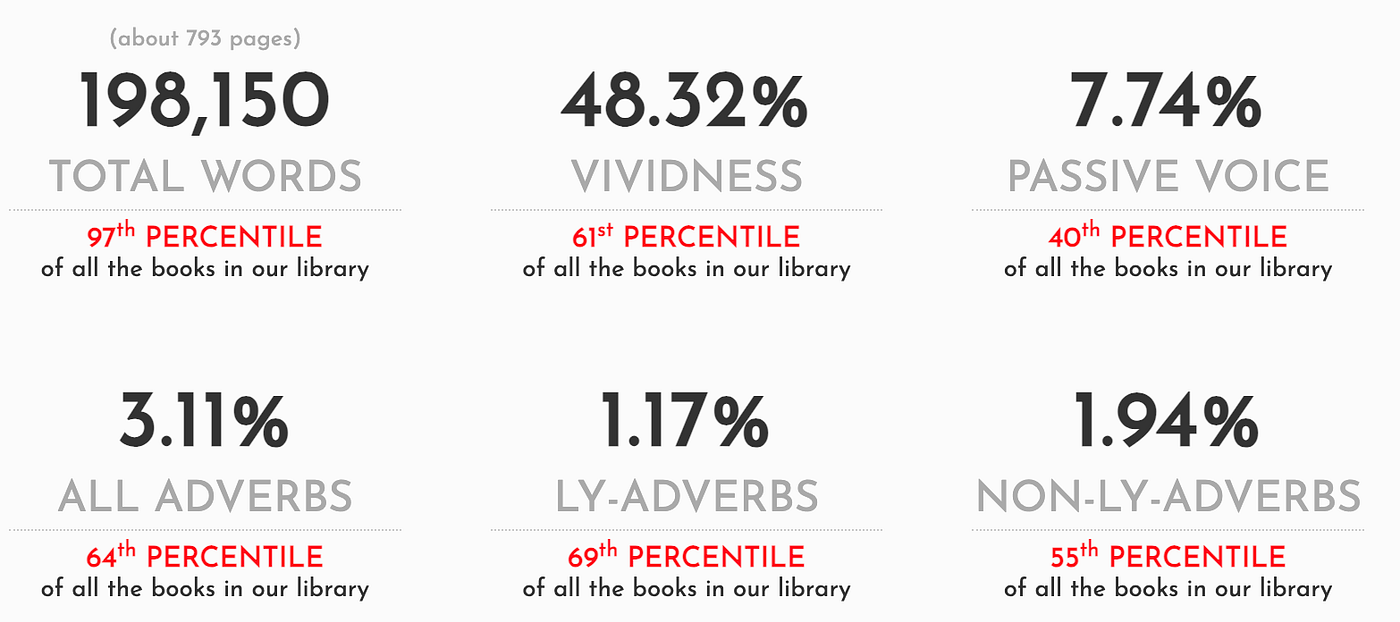
Not terribly useful, but maybe when plotted on a trend-line over time, or compared across genres, it could uncover some interesting insights. Hard to say without fooling around with it. But it doesn’t seem terribly harmful, either.
So why the outrage? Why the death threats and verbal abuse?
Who are all these angry people that came out of the woodwork to rake this random smalltime hacker over the coals?
There are two main buckets I see, here.
Bucket one: the anti-piracy folks. These writers speculated that ProseCraft likely needed full-text novels to run analytics on them, and that such a large database probably wasn’t paid for out-of-pocket by just one dude.
This is a bucket of people I won’t directly address, because we just fundamentally disagree in our values. For purposes like analytics and research—even if that aggregated data is later sold, e.g. in a scientific journal or as part of consulting services—ripping a book is perfectly fine. I could do much the same by taking my library card, checking a book out of a digital library, analyzing it, and saving those numbers in my notes.
If these people were at all consistent in their views they’d probably also dunk on tools like Sci-Hub or Libby. Maybe they could learn a lesson or two from authors like Wallace Wang, who wrote Steal This Computer Book 4.0. You can probably imagine what his take would be.
Bucket two: the folks who don’t want their work to be used in profit-generating AI. This seemed to be the larger cohort. It wasn’t the data-sourcing that was a problem—it was the fact that it might be used to train some sort of algorithm that a company could use to make money.
The creator of ProseCraft also had a monetized product called Shaxpir, and he made the fatal mistake of mentioning AI somewhere within a 3-mile radius of its product spec. This was all people needed to jump down his throat.

But AI is a broad umbrella term. Some of it can be genuinely harmful—but a lot of it is so unsophisticated that it doesn’t even have the capacity to hurt the writing community.
The latter is what was at play, here.
Technical breakdown
After caving to pressure, Shaxpir removed the features that used algorithms trained on authors’ works. While tragic, it’s useful for our analysis because he identifies the features outright and we don’t have to speculate what he was doing.
These features were:
- A thesaurus function
- A “vividness” and sentiment analysis of prose
- Linguistic percentile analysis
Thesaurus
This feature lets you swap out a word with another one that makes sense given the context. Kind of like a regular thesaurus and its list of synonyms, but far more context-aware.

How does it work?
By using a natural-language processing algorithm that is now positively medieval: word2vec.
How do you train it? In broad strokes:
- You represent every word as a set of random GPS coordinates that says where the word is in your “word-space”. Numerical representations of words are what let you do fun things like assert that “King - Man + Woman = Queen” and other cute little operations like that.
- You chop up the text corpus—in this case, novels—into pairs of words that “co-occur”. Whether that means being right next to each other, or just sharing a clause, a sentence, or a whole document is up to you.
- You jiggle the coordinates of each word such that their distance from each other roughly matches their co-occurrence rate in your document database.
- Ta-da! You now have a word-space where each word-coordinate is representative of what other words they tend to appear by, and can be used in a narrative-focused thesaurus.
None of this exploits an author’s voice, talent, or style—like maybe some modern Large Language Models might.
It certainly can’t be used to, say, spam beloved sci-fi magazines with factory-made submissions, or mimic an author’s brand to churn out derivative works. You know, actual harmful uses of AI in literature.
ProseCraft and Shaxpir were barely a layer removed from just counting word-pairs. This family of statistical modeling is so unsophisticated that they’re called “bag-of-words” models—because that’s what they do. Put a bunch of words disembodied from their sentences into a bag, and count them up.
Vividness and sentiment analysis
The vividness-analysis feature tells you how many “vivid” sensory words a block of text invokes as well as how intense they are.

This feature might need:
- Part-of-speech tagging, which is a classic computational linguistics problem people have been hacking at for a while. This can isolate nouns, verbs, and adjectives.
- Vividness classification, to identify words that count as “vivid”. The Shaxpir blog makes it seem as though they identified which nouns and verbs were vivid by hand. This takes a lot of elbow grease, and means that they personally dedicated time to enrich the dataset.
- Vividness scoring, since not all vivid words were made equal. The intensity of the vividness appears to be based on word-frequency: so they’d count up how often these words showed up in their library of authors’ works, and the ones that were rarer across the corpus would be more vivid. These rarity metrics would be mapped to scores between 0 and 10.
For sentiment analysis, the analytical technique is much the same, except instead of “vivid” words you’re instead tracking words with positive and negative valence—and the average valence for a block of text is its sentiment.
Again, none of this exploits authors or makes it harder for them to make a living. The words are all ground into a homogenous paste and the software only looks at counts and frequencies—there’s nothing “stolen” here.

Determining that the letter “E” is the most frequently used letter in the English language doesn’t demand consent from every single person who ever picked up a pen—and this kind of statistical analysis certainly doesn’t require buy-in from or remuneration to authors in this text corpus.
Would you really charge someone if they asked you how many times you use the words “tequila” or “underpants” in your sentences? I doubt it.
Linguistic percentiles
This is a meta-feature that works on top of the other features delivered by ProseCraft and Shaxpir—and tells you how a certain metric compares with the rest of the library.

This puts a work in rank-order based on some metric, and then tells you how it placed.
That’s it.
There’s nothing harmful here.
These authors boiled themselves up into a tizzy over next-to-nothing, and then ruined some dude’s day over it because he smelled vaguely tech-adjacent.
Goliaths playing at David
The thing that pisses me off most about this whole affair is how sneering and sanctimonious the offending authors were while engaging in this absolutely unfounded crusade.
They came into the situation with an attitude like they were victims, and it was they who were rising up against some sort of powerful oppressor.
Meanwhile, casual observers would note that:
- Benji Smith, the indie creator of Shaxpir, had less than two thousand followers on Twitter and likely even fewer users of his product, which seemed to have been inactive for several years.
- The authors that dogpiled him were people like Jeff VanderMeer—who has a fucking Hollywood movie made from his books, with around 70,000 Twitter followers—and Robert Brockway, a Cracked-writer turned novelist with 22,000 followers. These people are, compared to Benji, titans.

But the way they speak makes it sound like they just had some kind of world-changing revolution against an empire. Look at this silly nonsense:
Every single one of these “revolutionaries” is hyping themselves up thinking that they just went up against The Man and won—
But guess what, you self-righteous fucks?
You are The Man.
